Building a Modern Data Mesh Framework with Snowflake
Written on
Chapter 1: Introduction to Data Mesh
Understanding the concept of Data Mesh is crucial, as it primarily offers a fresh organizational perspective rather than solely addressing technical issues. To effectively implement a Data Mesh framework, consider these four guiding principles:
Principle 1: Decentralized Data Ownership and Architecture
A Data Mesh aims to cater to the specific needs of individual business units. This can involve the creation of one or more Data Lakehouses.
Principle 2: Treating Data as a Product
The architecture of a Data Lakehouse facilitates the management of data as a product, allowing domain-specific teams to have full control over the data lifecycle.
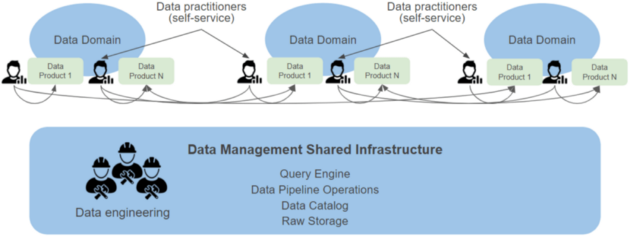
Architecture of a Data Mesh — Source: upsolver.com
Principle 3: Self-Service Data Infrastructure
Users should be able to access data through self-service BI tools, while Data Scientists can also utilize the same data to develop their models.
Principle 4: Federated Computational Governance
Data must be secured and distributed through a role-based approach. Data catalogs can be particularly useful for this purpose.
A Data Mesh organizes and manages data within an organization by fostering autonomy and ownership at the team level. It emphasizes a decentralized data architecture where teams are responsible for both the data they generate and consume, rather than relying on a centralized management approach.
Chapter 2: Steps to Establish a Data Mesh
To initiate the process of building a Data Mesh, follow these steps:
Step 1: Define Your Governance Model
Start by outlining the governance framework for your Data Mesh. This should detail how teams can access and utilize data, as well as how data ownership will be structured.
Step 2: Identify Data Sources and Load into Snowflake
Next, pinpoint all the data sources that will be part of your Data Mesh. This includes both structured and unstructured data from various origins, such as databases, APIs, and file systems. Once identified, load this data into Snowflake using ETL or ELT processes, transforming and cleansing the data as necessary. Utilize Snowflake’s built-in data loading tools, such as the Snowflake Data Loader or the Snowpipe API.
How Roche Securely Scales a Data Mesh on Snowflake Discover how Roche effectively implements a Data Mesh architecture using Snowflake, ensuring security and scalability.
Step 3: Create Data Views, Datasets, and a Data Catalog
After the data has been cleaned and transformed, create datasets and data views to share with relevant teams. Leverage Snowflake’s virtual warehouse and data-sharing capabilities. Additionally, establish a data catalog to help users locate data and understand its context.
Step 4: Monitor and Optimize Performance
As teams start utilizing the data mesh, continuous monitoring and optimization are essential to ensure efficient data access and usage. This may include indexing, partitioning, and optimizing queries.
By following these steps, you can build a Data Mesh with Snowflake, promoting a decentralized data architecture that fosters team ownership and autonomy.
Snowflake for Data Mesh Explore how Snowflake supports the Data Mesh concept, offering tools and frameworks to enhance data management within organizations.
Chapter 3: Data Mesh vs Data Fabric
Understanding the distinctions between Data Mesh and Data Fabric is vital for implementing the right strategy for your organization.
Sources and Further Readings
[1] Michael Armbrust, Ali Ghodsi, Bharath Gowda, Arsalan Tavakoli-Shiraji, Reynold Xin, and Matei Zaharia, Frequently Asked Questions About the Data Lakehouse (2021)
[2] Upsolver.com, Demystifying the Data Mesh: a Quick “What is” and “How to” (2022)